

As generative AI tools such as ChatGPT, Google Gemini, Perplexity and more have a growing impact on our lives, there is increasing interest in influencing the output of the large language models (LLMs) that underly them.
What Does LLMO Mean?
LLMO (or LLM optimization) is the process of influencing the output of LLMs.
It is an emerging field but one that it’s worth paying attention to. Similar efforts to influence search engines, known as search engine optimization (SEO), are a huge industry (estimated at US$68.1 Billion in the year 2022 by Global Industry Analysts, Inc).
Note: you may see other terms being used in place of LLMO. For example, AI SEO, GAIO (generative AI optimization), AIO (AI optimization), AEO (AI Engine Optimization) or GEO (generative engine optimization). In all these cases, they’re generally talking about very much the same sort of thing.
What is the difference between SEO and LLMO?
Whereas SEO is the process of improving a website’s visibility in search engine results, LLMO is the process of improving a brand’s visibility in the output of AI-powered systems, e.g. in Google search’s AI summaries and in ChatGPT’s responses.
There’s some overlap between SEO and LLMO since some AI-powered systems do live web searches behind the scenes (so SEO helps with LLMO) and search engines such as Google are increasingly using LLMs to respond to search queries (so LLMO helps with SEO.)
What Can Influencing LLMs Achieve?
Influencing the output of LLMs can have far-reaching effects. In the commercial world alone these can include:
- Ensuring that a product or service is considered for a purchase decision
- Giving a favourable impression of a product or service
- Framing how someone approaches a purchase
Is LLMO Feasible?
There are challenges to effective LLMO, but research is already providing evidence that LLMO is not only possible but potentially very impactful.
“… these methods are capable of boosting source visibility by up to 40% in generative engine responses”
Authors of “GEO: Generative Engine Optimization”
What Does LLMO Involve?
When thinking about influencing the output of a large language model, you can consider two broad approaches:
- Influencing the model itself
- Influencing the context that is provided to the model as part of a particular request
Approach 1: Influencing Models Themselves
Influencing a model’s training data influences the resultant model
Each large language model is, in essence, a vast array of parameters known as ‘weights’. These weights are the result of a lengthy training process that makes use of huge quantities of content.
If you can somehow influence some of the content that is used for training a model, you’ll be influencing the resultant model.
Training data includes content from the internet
The content that has been used to train large language models includes large datasets such as the following:
- Common Crawl (an open source collection of web data)
- Wikipedia
- Large collections of public domain books
OpenAI, for example, used the following mix of data to train their GPT-3 model (per their 2020 “Language Models are Few-Shot Learners” paper):
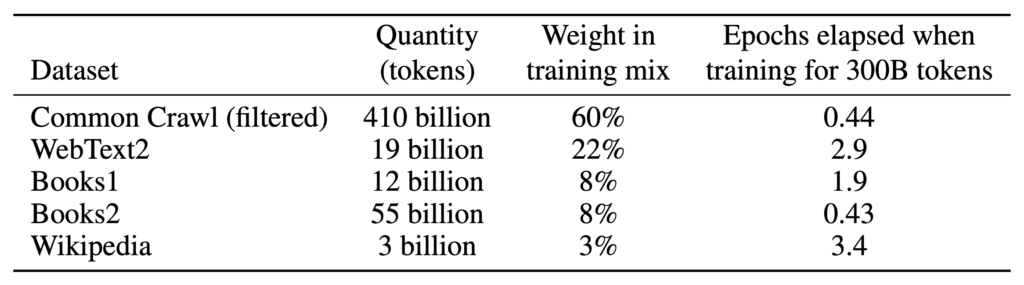
Note that the different data sources were given different ‘weightings’ in the training. A given paragraph would have about 7 times more influence on a model if it appeared on Wikipedia than if it appeared on a less authoritative website.
Over time, LLM providers have been looking for larger and larger sets of data to use in training their models so, if anything, are likely to use even more of the content on the web for training now.
Content you place on the web may be part of the ‘training set’ for future LLMs
Given this, if you can place favorable content on the web, then there’s a good chance it will be scraped and used as part of a future LLM’s training set. It’ll then influence (to some extent) how the resultant model will behave.
Content in ‘high quality’ corners of the internet, such as on Wikipedia, may well influence the model more than the same content elsewhere.
The amount of content you’ll need to usefully influence an LLM will be proportional to how much it’s already discussed online
The more commonly-discussed a given topic, the more content you’ll need to influence in order to significantly influence the output of future LLMs regarding that topic.
Conversely, the less-commonly-discussed a given topic, the less content you’ll tend to need.
This is largely just online PR
If the ideas above sounded familiar, that’s probably because what it comes down to is basically just traditional online PR — getting people talking positively about your product or service online. You don’t really need to do anything particularly different.
When it comes to LLMO-specific efforts, then, we need to look elsewhere.
But apart from influencing the AI models themselves, what can we do?
Approach 2: Influencing the Context Provided to Models
AI also ‘looks things up’
Increasingly, large language models are being hooked up to data sources that allow them to ‘look things up’ on the fly rather than rely on the knowledge encoded in them through their training. In the case of LLM-powered internet search or answer engines such as Bing Chat, Google Bard and Perplexity, they can look things up virtually anywhere on the public internet.
Such systems typically retrieve a number of pieces of content from the internet that they hope will be useful in formulating a response, then feed that content as ‘context’ to an underlying LLM.
Influencing what AI ‘looks up’ can influence what it says
If you have control over the content that is passed to the LLM, then you can potentially influence the output of the LLM.
Breaking this down further, there are two things you can do:
- make sure that your content is retrieved
- make sure that, if your content is retrieved, it influences the output as favorably as possible
2(a) Making Sure Your Content is Retrieved
This is about trying to ensure a system retrieves the content you want rather than other things it could retrieve.
Behind the scenes, generative AI-enhanced search and answer systems use search engines to find content that is likely to be helpful in answering a given query (e.g. the top 5 search results for a given query). They then pass some or all of the content from those results to their LLM.
To make it more likely that your content is passed to the LLM, then, you need to make it more likely that your content is in the top results returned by the search engine that the system is using. And that’s largely just traditional SEO.
Over time, it’s possible that the search engines used as part of these ‘retrieval augmented generation’ (RAG) systems will diverge in nature from human-facing search engines as the companies providing them better understand what is most helpful in the RAG context. If so, organizations may want to target SEO efforts specifically towards influencing these LLM-focused search engines.
2(b) Making Sure That, if Your Content is Retrieved, it Influences the Output as Favourably as Possible
Assuming you can get your content retrieved and passed to the LLM, what do you ideally want it to say?
This is an area ripe for exploration and where experimentation is very much possible.
Some early findings in this area were reported in the (not yet peer-reviewed, as of January 2024) paper “GEO: Generative Engine Optimization,” by researchers at Princeton, Georgia Tech, The Allen Institute for AI and IIT Delhi. They found specific types of changes to content passed on an LLM had a significant impact on the visibility of the sources of that content in the LLM’s output. I discuss it a little further here.
To the extent that you trust these findings, you may want to make sure your content includes healthy authority-boosting elements such as citations, quotations from relevant sources, and statistics.
What’s Next?
LLMO is an emerging field and one that is likely to rise in prominence over the coming years. For now, few people are focussing on it, so if you’re able to leverage it successfully, you may have a valuable head start over your competitors.
Have a look at these LLMO best practices to find concrete steps you can start taking now.
References
- GEO (Generative Engine Optimization), the Future of SEO (?) by Ann Smarty, December 2023
- GEO: Generative Engine Optimization by Aggarwal et al, November 2023
- LLM optimization: Can you influence generative AI outputs? by Olaf Kopp, October 2023
- The Ultimate Guide to LLMO, GEO & AIO by Malte Landwehr, January 2024
Comments
One response to “The Beginner’s Guide to LLMO”
good stuff.